Big and Little Endian
在内存中存储Words
假设一个32 bit(90AB12CD, 为16进制数),每个16进制数为4 bits,我们需要8个16进制数表示一个32 bit的值,这4 bytes为:90, AB, 12, CD,每个字节需要两个16进制数
这个32 bit的数在内存中有两种方式存储
大端字节
在大端字节里,地址最低位存放数的最高位(store the most significant byte in the smallest address),中文解释起来有点怪,存放如例图
在小端字节里,地址最低位存放数的最低位(store the least significant byte in the smallest address), 存放如例图
为什么存在这两种方式?
这个问题我没有细致研究,如果你在网络上传输数据,一定需要知道计算机是大端还是小端字节,要不然如果你传的是相反端的字节,读起来就可能会出错,因为一般基本数据类型可不只有占一个字节的char型,还有float, int等类型,如果涉及多字节传输,自然要考虑Endian的类型
可以通过union测试系统的大小端,如下
union
{
int i;
char a;
}C;
C.i = 1;
//打印字符a,如果输出为1,即为小端,否则,则为大端
printf("%d", C.a);分析:
因为union里是共享内存空间的,而且对一个变量赋值会覆盖其他变量占用共享空间的值,union的空间大小为占用最大空间类型的大小,如上例,sizeof(C)的大小为4 bytes,因为int占4 bytes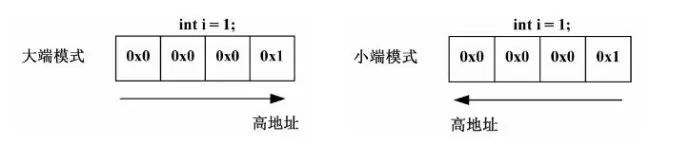
可以参考这篇文章
Big and Little Endian